Abstract
The National Football League is a multi-billion dollar industry, in which evaluating a player’s value to the team is of the utmost importance for negotiating contracts under the league-wide salary cap and maintaining long periods of success. Value can be defined in a number of ways, but we identified making the Hall of Fame, number of career Pro Bowls, career games played, and career games started as four good benchmarks, and set out to predict these targets from a player’s statistics in a given year. Using data scraped from pro-football-reference.com, we evaluated Naive Bayes, Logistic Regression, Decision Tree, and Random Forest classifiers to generate target classifications from 93 numeric playing statistics.
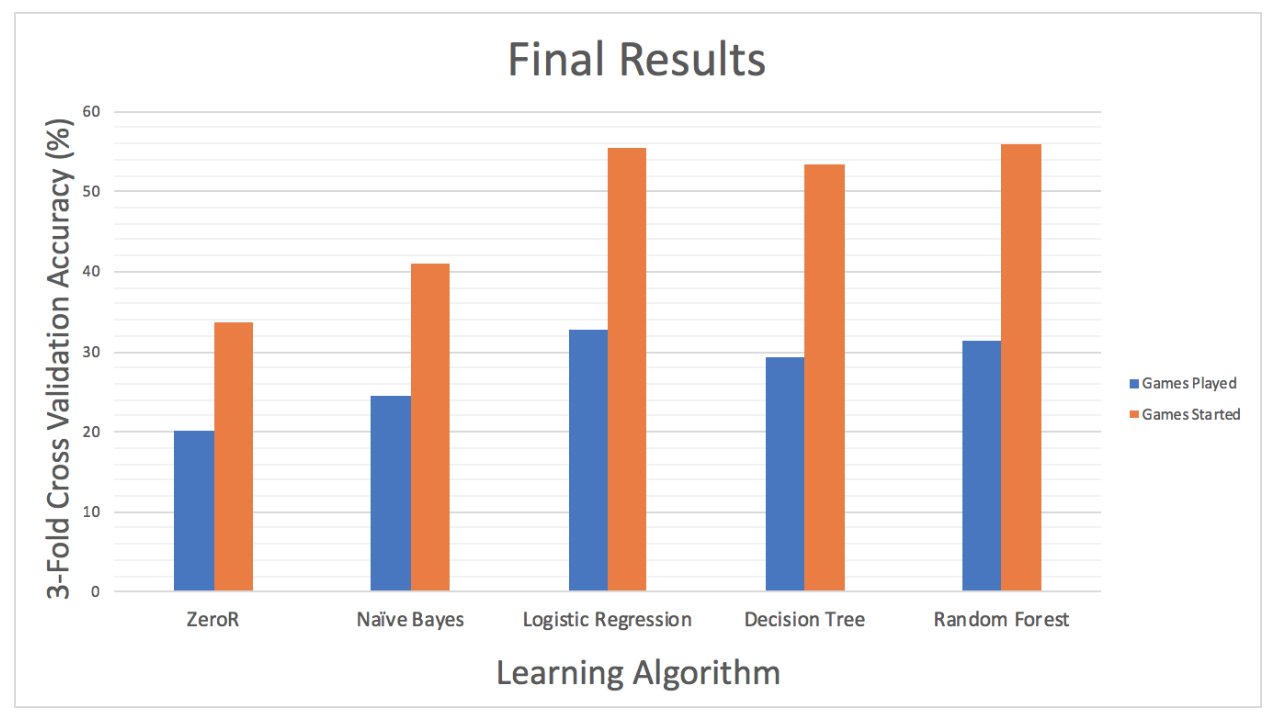
Overall, our classifiers performed much better than random for the games played and games started target variables, and poorly for the Hall of Fame and Pro Bowl variables. Because achieving such high honors is so rare, it was incredibly difficult to beat a ZeroR classifier that simply predicted “0” for Hall of Fame induction or number of Pro Bowls (above 99% accuracy). For career games played and started, on the other hand, we achieved promising results by discretizing our target variables into equally frequent categories and trying a number of classifiers (results summarized in the figure below). While age consistently factored in heavily as an important feature, other key attributes were dependent on position, which was implicitly represented through the presence and absence of certain statistics.
Overall, our classifiers performed much better than random for the games played and games started target variables, and poorly for the Hall of Fame and Pro Bowl variables. Because achieving such high honors is so rare, it was incredibly difficult to beat a ZeroR classifier that simply predicted “0” for Hall of Fame induction or number of Pro Bowls (above 99% accuracy). For career games played and started, on the other hand, we achieved promising results by discretizing our target variables into equally frequent categories and trying a number of classifiers (results summarized in the figure below). While age consistently factored in heavily as an important feature, other key attributes were dependent on position, which was implicitly represented through the presence and absence of certain statistics.